群体药动学模型的组成部分
付永超 / 2019-12-27
群体药动学模型发包含一下这些组成部分
- PK模型
- 误差模型
- 参数结构
- 协变量关系
报告时应报告上述的每一部分
PK模型
对与PK部分的报告,一般分为几种情况
1.仅通过文字描述所使用的PK模型和参数化方式,仅适用于使用经典的PK模型的时候,
2.使用微分方程描述完整的模型,最为常用的形式,使读者可以很好的理解模型
3.使用宏观方程/多指数项描述的方程,少见
4.直接使用特定的代码语言描述模型,一般作为辅助手段,并不单独使用
5.使用模型结构示意图描述PK模型,一般作为辅助手段被经常使用,并不单独使用
误差模型
误差模型通常都比较简单,所以一般使用一下两种方式就可满足描述清楚的需求
1.通过文字描述所使用的误差模型,
2.通过方程描述所使用的误差模型,
如果遇到复杂的误差模型,可能会结合代码一并报告。
参数结构
参数结构描述一般是通过方程的形式展现辅以文字描述,因为一般常见的都是对数正态分布或者常数正态分布。
协变量关系
协变量的关系一般都使用方程的方式表示,因为文字描述太复杂,而且不仅要考虑协变量关系本身的公式还需要考虑它与参数结构的组合方式,所以一般在报告参数结构后,额外的再协变量关系报告部分把协变量关系写入参数结构方程中在报告一次出来。
具体应报告那些内容
PK模型
1.仅通过文字描述所使用的PK模型和参数化方式,仅适用于使用经典的PK模型的时候,
分别说明吸收(0级、1级、混合、弥漫式方程、血管内静注)、分布(1房室、2房室、3房室)、消除(0级、1级、混合、弥漫式方程)部分的情况,以及参数化的方式(宏观、微观、清除率)。
2.使用微分方程描述完整的模型,最为常用的形式,使读者可以很好的理解模型
分别描述模型中每一个房室的微分方程,包括中央室/周边房室、消除室。
3.使用宏观方程/多指数项描述的方程,少见
一般仅描述中央室的浓度方程
4.直接使用特定的代码语言描述模型,一般作为辅助手段,并不单独使用
使用Phoenix建模语言、等建模语言描述模型
5.使用模型结构示意图描述PK模型,一般作为辅助手段被经常使用,并不单独使用
可以参考Phoenix中的结构示意图
误差模型
通过文字描述误差模型类型(加和、比例、混合、其他等),然后辅以公式说明误差模型,描述误差模型的方程中使用ε(epsilon,伊普西隆)表示随机误差这个随机变量,ε属于一个正态分布,该正态分布的均值为0,方差为西格玛的平方,即ε~N(0, σ2),报告结果时,报告伊普西隆的标准差西格玛的值,在Phoenix中该值包含在Theta报表中,名字为"stdev0".
参数结构
参数结构描述一般是通过方程的形式展现辅以文字描述,因为一般常见的都是对数正态分布或者常数正态分布。
此部分应声明
- 哪些参数仅估算群体典型值,而不估算个体间变异
- 哪些参数固定了群体典型值,不估算个体间变异
- 以及一些其他的固定参数的或不管算参数的情况
这一部分一般报告参数的值,除非是基础模型,不包含协变量关系。
如果报告,且个体间变异为对数正态分布则需报告
群体典型值的"估计值(Estimate)"
群体典型值的"百分比化的相对标准误(%RSE,Phoenix中为CV%)"
个体间变异的"变异系数(%CV,)"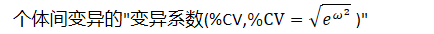
个体间变异的"百分比化的相对标准误(%RSE,Phoenix中为CV%)"
先写一半放在这里,之后慢慢的补全。